Наверняка многие из вас знают, что представляет собой продукт VMware vRealize Operations 6.x (а некоторые и используют его в производственной среде), предназначенный для мониторинга производительности виртуальной инфраструктуры VMware vSphere, анализа ее состояния, планирования и решения проблем.
Добрые ребята с сайта vXpresss сделали уже готовый дэшборд для vRealize Operations, который включает в себя 15 объектов "Super Metrics", 6 представлений (Views) и один кастомизированный XML. Визуально дэшборд выглядит следующим образом (кликабельно):
То, что могло бы занять у вас часы настройки, теперь можно просто развернуть за 10 минут, используя готовый модуль.
Опишем эти представления:
1 - список ваших кластеров, которые вы мониторите через vRealize Operations Manager 6.x.
2 - этот виджет отображает ключевые метрики с точки зрения процессора, памяти и хранилищ датацентра.
3 - данный виджет показывает пиковые и средние значения использования CPU виртуальной машиной в выбранном кластере. Это позволяет видеть нагруженные машины в вашем окружении.
4 - этот виджет похож на предыдущий только здесь отображается метрика Contention% для CPU (ожидание ресурсов со стороны ВМ), которая является одной из ключевых в плане производительности.
5 - виджет показывает пиковые и средние значения использования памяти (Memory) виртуальной машиной в выбранном кластере. Это позволяет видеть тяжелые по памяти машины в вашем окружении.
6 - по аналогии с CPU Contention, для памяти используется метрика Memory Contention % - отображаются также ее средние и пиковые значения. Ее рост показывает, что ваши машины скоро будут конкурировать за ресурсы оперативной памяти (и начнется memory overcommitment).
7 - этот виджет показывает пиковые и средние значения IOPS для виртуальной машины в выбранном кластере.
8 - в дополнение к IOPS, здесь можно видеть пиковое и среднее значение задержки в дисковой подсистеме (Virtual Disk latency), которая возникает при работе виртуальных машин.
Скачать описанный дэшборд и его компоненты можно по этим ссылкам:
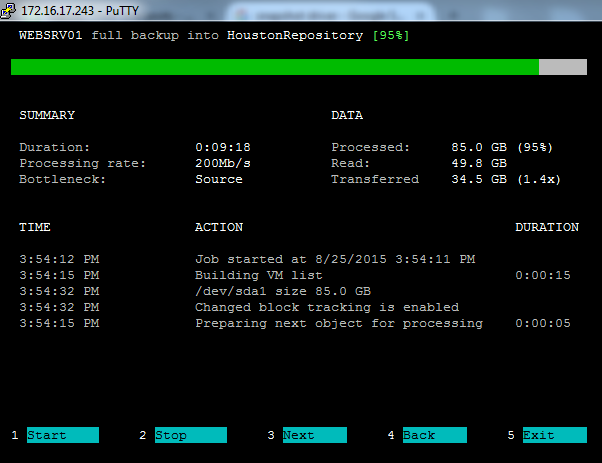
Недавно мы писали о серьезном баге в механизме Changed Block Tracking (CBT) платформы VMware vSphere 6, который приводит к тому, что инкрементальные резервные копии виртуальных машин оказываются невосстановимыми.
Это, конечно, очень неприятное известие, но не для пользователей решения Veeam Backup and Replication, так как там есть возможность отключить поддержку глючной технологии CBT. Для этого идем в свойства задачи резервного копирования (Edit Backup Job) и выбираем там пункт "Advanced":
И на вкладке vSphere расширенных настроек убираем галку "Use changed block tracking data (recommended)":
Это приведет к тому, что при создании инкрементальных резервных копий Veeam B&R при следующем запуске задачи не будет использовать технологию CBT для отслеживания изменившихся блоков, а значит при создании инкремента бэкапа будут сравниваться все блоки диска ВМ на отличия от бэкапа. Это займет большее время, но ваша резервная копия гарантированно окажется восстановимой.
Такое вот приятное отличие Veeam Backup and Replication от других продуктов для резервного копирования позволит вам продолжать использовать технологии резервного копирования в производственной среде в то время как все остальные пользователи (которые без B&R) страдают и воют от безысходности.
На сайте проекта VMware Labs, где сотрудники VMware частенько публикуют различного рода утилиты для инфраструктуры VMware vSphere, появилось обновление очень полезной штуки, которое все очень давно ждали - VMware Auto Deploy GUI. Напомним, что о прошлой верcии этого средства мы писали вот тут.
Теперь вы можете проводить преднастройку профилей и развертывание новых хостов VMware ESXi 6 для Stateless-окружения прямо из графического интерфейса VMware vSphere Client:
Auto Deploy GUI - это плагин к vSphere Client, реализующий основные функции VMware vSphere Auto Deploy, такие как:
Создание/редактирование правил соответствия хостов и профилей образов.
Проверка соответствия хостов этим правилам и восстановление этого соответствия.
Новые возможности последней версии Auto Deploy GUI:
Поддержка VMware vSphere 6.0.
В мастере Image Profile Wizard появились новые функции "VIB filter".
Новые средства "PXE Host List and Boot Configuration troubleshooting" для решения проблем с загрузкой хостов.
Надо отметить, что это последняя версия Auto Deploy GUI, которая поддерживает VMware vSphere версии 5.0. Скачать VMware Auto Deploy GUI можно по этой ссылке. Ну и порекомендуем очень полезный документ "VMware Auto Deploy GUI Practical Guide".
Как-то раз мы писали про баг в VMware vSphere 5.5 (и более ранних версиях), заключавшийся в том, что при увеличении виртуальных дисков машин с включенной технологией Changed Block Tracking (CBT) их резервные копии оказывались невалидными и не подлежащими восстановлению. Эта ошибка была через некоторое время пофикшена.
Суть критического бага в том, что операции ввода-вывода, сделанные во время консолидации снапшота ВМ в процессе снятия резервной копии, могут быть потеряны. Для первого бэкапа в этом нет ничего страшного, а вот вызываемая во второй раз функция QueryDiskChangedAreas технологии CBT не учитывает потерянные операции ввода-вывода, а соответственно при восстановлении из резервной копии такой бэкап будет неконсистентным. То есть баг намного более серьезный, чем был в версии vSphere 5.5 (там надо были задеты только ВМ, диски которых увеличивали, а тут любая ВМ подвержена багу).
На данный момент решения этой проблемы нет, надо ждать исправления ошибки. Пока VMware предлагает на выбор 3 варианта:
Сделать даунгрейд хостов ESXi на версию 5.5, а версию virtual hardware 11 понизить на 10.
Делать полные бэкапы виртуальных машин (full backups) вместо инкрементальных.
Выключать виртуальные машины во время инкрементального бэкапа, чтобы у них не было никаких IO, которые могут потеряться.
Как вы понимаете, ни один из этих вариантов неприемлем в условиях нормальной работы производственной среды. Мы оповестим вас об исправлении ошибки, ну а пока поздравляем службу контроля качества компании VMware с очередной лажей!
P.S. Пока делайте полные бэкапы критичных систем. И следите за новостями от Veeam.
Сегодняшняя статья расскажет вам ещё об одной функции моего PowerShell-модуля для управления виртуальной инфраструктурой VMware - Vi-Module. Первая статья этой серии с описанием самого модуля находится здесь. Функция Convert-VmdkThin2EZThick. Как вы уже поняли из её названия, функция конвертирует все «тонкие» (Thin Provision) виртуальные диски виртуальной машины в диски типа Thick Provision Eager Zeroed.
3 года назад мы писали об утилите ESXi5 Community Packaging Tools 2.0, которая позволяет создавать собственные пакеты для VMware ESXi в форматах VIB (VMware Installation Bundle) and ZIP (VMware Offline Bundle). В результате VIB-файлы получают уровень доверия (acceptance level) Community Supported. Зачастую, эти утилиты необходимы пользователям для включения сторонних драйверов устройств в состав дистрибутива платформы ESXi, которые отсутствуют в стандартном комплекте поставки.
На самом деле, изменений было сделано не так много, но они есть и важные:
Появилась полная поддержка VMware vSphere 6 (именно поэтому "ESXi5 Community Packaging Tools" (ESXi5-CPT) переименованы в "ESXi Community Packaging Tools" (ESXi-CPT).
Пакетный сценарий TGZ2VIB5.cmd обновлен до версии 2.3.
Пофикшено название уровня доверия (acceptance level) "certified" (раньше он назывался "vmware").
Добавлены пресеты конфигураций "ESXi 6.0+ driver" и "VMware Tools" (tools-light.vib). Теперь вы можете создать свой пакет VMware Tools для распространения в гостевых ОС на базе гипервизора ESXi!
Добавлена поддержка типа VIB-пакета (vibType) "locker".
Пакетный файл VIB2ZIP.cmd обновился до версии 1.3 - туда были добавлен выбор настроек совместимости для VMware ESXi.
Видео о создани VMware Offline Bundle с помощью VIB2ZIP:
Скачать ESXi Community Packaging Tools версии 2.3 можно по этой ссылке.
Многие из вас знают, что в VMware vSphere есть такой режим работы виртуальных дисков, как Raw Device Mapping (RDM), который позволяет напрямую использовать блочное устройство хранения без создания на нем файловой системы VMFS. Тома RDM бывают pRDM (physical) и vRDM (virtual), то есть могут работать в режиме физической и виртуальной совместимости. При работе томов в режиме виртуальной совместимости они очень похожи на VMFS-тома (и используются очень редко), а вот режим физической совместимости имеет некоторые преимущества перед VMFS и довольно часто используется в крупных предприятиях.
Итак, для чего может быть полезен pRDM:
Администратору требуется использовать специальное ПО от производителя массива, которое работает с LUN напрямую. Например, для создания снапшотов тома, реплики базы данных или ПО, работающее с технологией VSS на уровне тома.
Старые данные приложений, которые еще не удалось перенести в виртуальные диски VMDK.
Виртуальная машина нуждается в прямом выполнении команд к тому RDM (например, управляющие SCSI-команды, которые блокируются слоем SCSI в VMkernel).
Перейдем к рассмотрению схемы решения VMware Site Recovery Manager (SRM):
Как вы знаете, продукт VMware SRM может использовать репликацию уровня массива (синхронную) или технологию vSphere Replication (асинхронную). Как мы писали вот тут, если вы используете репликацию уровня массива, то поддерживаются тома pRDM и vRDM, а вот если vSphere Replication, то репликация физических RDM будет невозможна.
Далее мы будем говорить о репликации уровня дискового массива томов pRDM, как о самом часто встречающемся случае.
Если говорить об уровне Storage Replication Adapter (SRA), который предоставляется производителем массива и которым оперирует SRM, то SRA вообще ничего не знает о томах VMFS, то есть о том, какого типа LUN реплицируется, и что на нем находится.
Он оперирует понятием только серийного номера тома, в чем можно убедиться, заглянув в XML-лог SRA:
Тут видно, что после серийного номера есть еще и имя тома - в нашем случае SRMRDM0 и SRMVMFS, а в остальном устройства обрабатываются одинаково.
SRM обрабатывает RDM-диски похожим на VMFS образом. Однако RDM-том не видится в качестве защищаемых хранилищ в консоли SRM, поэтому чтобы добавить такой диск, нужно добавить виртуальную машину, к которой он присоединен, в Protection Group (PG).
Допустим, мы добавили такую машину в PG, а в консоли SRM получили вот такое сообщение:
Device not found: Hard disk 3
Это значит одно из двух:
Не настроена репликация RDM-тома на резервную площадку.
Репликация тома настроена, но SRM еще не обнаружил его.
В первом случае вам нужно заняться настройкой репликации на уровне дискового массива и SRA. А во втором случае нужно пойти в настройки SRA->Manage->Array Pairs и нажать там кнопку "Обновить":
Этот том после этого должен появиться в списке реплицируемых устройств:
Далее в настройках защиты ВМ в Protection Group можно увидеть, что данный том видится и защищен:
Добавление RDM-диска к уже защищенной SRM виртуальной машине
Если вы просто подцепите диск такой ВМ, то увидите вот такую ошибку:
There are configuration issues with associated VMs
Потому, что даже если вы настроили репликацию RDM-диска на уровне дискового массива и SRA (как это описано выше), он автоматически не подцепится в настройки - нужно запустить редактирование Protection Group заново, и там уже будет будет виден RDM-том в разделе Datastore groups (если репликация корректно настроена):
Помните также, что SRM автоматически запускает обнаружение новых устройств каждые 24 часа по умолчанию.
Мы часто пишем о решении для создания отказоустойчивых хранилищ StarWind Virtual SAN, которое помогает существенно сэкономить при построении инфраструктуры хранения виртуальных машин на платформах VMware vSphere и Microsoft Hyper-V. Вот в этой статье мы писали о том, что 3 узла для кластера - это лучше, надежнее и экономнее (в пересчете на единицу емкости), чем 2. Это обеспечивает аптайм хранилищ до 99.9999%. Но иногда и 2 узла вполне достаточно с точки зрения экономии на программном и аппаратном обеспечении.
Гостевая статья нашего спонсора - компании ИТ-ГРАД, предоставляющей услуги виртуальных машин VMware в аренду. В этой статье речь пойдет о плюсах интеграции среды виртуализации VMware и систем хранения NetApp. В частности, продолжим разбираться с VAAI и посмотрим, как использование такой связки может помочь в проектах по разработке ПО.
Некоторое время назад мы писали о решении VMware vRealize Automation, которое появилось в результате ребрендинга продукта vCloud Automation, который предназначен для автоматизации операций в облачной инфраструктуре (в том числе гетерогенной и гибридной) на базе различных гипервизоров (не только VMware vSphere) .
Анонс новой версии VMware vRealize Automation 7 был сделан еще на VMworld Europe 2015, но так как обновление до сих пор не вышло, то еще не поздно рассказать вам о его новых возможностях.
Итак, давайте взглянем на новые возможности платформы VMware vRealize Automation 7:
1. Упрощенная процедура развертывания.
vRealize Automation 7 теперь не требует сложных операций при установке и настройке - развертывание решения происходит в едином интерфейсе с предлагаемыми настройками (также есть настройки аутентификации и Single Sign-On), которые потом можно просто изменить. Консоль выглядит намного приятнее (кликабельно):
Теперь в наглядном проектировщике инфраструктуры сервисов все делается, в основном, с помощью мыши, поэтому построить архитектуру ИТ-инфраструктуры вашего предприятия стало значительно проще:
3. Поддержка VMware NSX для сетевой топологии и инфраструктуры безопасности.
Теперь компоненты сетевой инфраструктуры VMware NSX доступны для построения сетевой архитектуры и инфраструктуры безопасности. Их можно переносить в визуальном редакторе с помощью Drag&Drop:
Это отменяет необходимость проектировать виртуализованную сетевую инфраструктуру за пределами vRealize Automation.
4. Формализованные описания сервисов и шаблоны.
Теперь шаблоны описания сервисов можно редактировать как текстовые файлы. Это позволяет более гибко подходить к проектированию и унификации архитектуры DevOps. Также поддерживаются системы управления версиями для хранения объектов - скриптов, шаблонов и сценариев рабочих процессов, файлов описания сервисов и т.п.
5. Улучшенная расширяемость решения для интеграции со сторонними облачными решениями.
Теперь vRealize Automation 7 имеет более широкие возможности по вызову операций в сторонних решениях для управления виртуальными инфраструктурами. Теперь появился Event Broker, который стандартизирует операции по передаче команд сторонним средствам.
Кроме того, был существенно доработан API и улучшена интеграция с облачной инфраструктурой Amazon AWS и VMware vCloud Air, что позволяет строить гибридные облака для предприятия (частное+публичное):
На момент написания заметки VMware vRealize Automation 7 еще не доступен для скачивания (обещают до конца 2015 года), но подписаться на оповещение о его доступности можно по этой ссылке.
На блоге vSphere появилась отличная статья о сервисах семейства vCenter Server Watchdog, которые обеспечивают мониторинг состояния различных компонентов vCenter, а также их восстановление в случае сбоев. Более подробно о них также можно прочитать в VMware vCenter Server 6.0 Availability Guide.
Итак, сервисы Watchdog бывают двух типов:
PID Watchdog - мониторит процессы, запущенные на vCenter Server.
API Watchdog - использует vSphere API для мониторинга функциональности vCenter Server.
Сервисы Watchdog пытаются рестартовать службы vCenter в случае их сбоя, а если это не помогает, то механизм VMware перезагружает виртуальную машину с сервером vCenter на другом хосте ESXi.
PID Watchdog
Эти службы инициализируются во время инициализации самого vCenter. Они мониторят только службы, которые активно работают, и если вы вручную остановили службу vCenter, поднимать он ее не будет. Службы PID Watchdog, контролируют только лишь наличие запущенных процессов, но не гарантируют, что они будут обслуживать запросы (например, vSphere Web Client будет обрабатывать подключения) - этим занимается API Watchdog.
Вот какие сервисы PID Watchdog бывают:
vmware-watchdog - этот watchdog обнаруживает сбои и перезапускает все не-Java службы на сервере vCenter Server Appliance (VCSA).
Java Service Wrapper - этот watchdog обрабатывает сбои всех Java-служб на VCSA и в ОС Windows.
Likewise Service Manager - данный watchdog отвечает за обработку отказов всех не-Java служб сервисов platform services.
Windows Service Control Manager - отвечает за обработку отказов всех не-Java служб на Windows.
vmware-watchdog
Это шелл-скрипт (/usr/bin/watchdog), который располагается на виртуальном модуле VCSA. Давайте посмотрим на его запущенные процессы:
Давайте разберем эти параметры на примере наиболее важной службы VPXD:
-a
-s vpxd
-u 3600
-q 2
Это означает, что:
vpxd (-s vpxd) запущен (started), для него работает мониторинг, и он будет перезапущен максимум дважды в случае сбоя (-q 2). Если это не удастся в третий раз при минимальном аптайме 1 час (-u 3600 - число секунд), виртуальная машина будет перезагружена (-a).
Он основан на Tanuki Java Service Wrapper и нужен, чтобы обнаруживать сбои в Java-службах vCenter (как обычного, так и виртуального модуля vCSA). Вот какие службы мониторятся:
Если Java-приложение или JVM (Java Virtual Machine) падает, то перезапускается JVM и приложение.
Likewise Service Manager
Это сторонние средства Likewise Open stack от компании BeyondTrust, которые мониторят доступность следующих служб, относящихся к Platform Services среды vCenter:
VMware Directory Service (vmdir)
VMware Authentication Framework (vmafd, который содержит хранилище сертификатов VMware Endpoint Certificate Store, VECS)
VMware Certificate Authority (vmca)
Likewise Service Manager следит за этими сервисами и перезапускает их в случае сбоя или если они вываливаются.
mgmt01vc01.sddc.local:~ # /opt/likewise/bin/lwsm list | grep vm vmafd running (standalone: 5505) vmca running (standalone: 5560) vmdir running (standalone: 5600)
Вместо параметра list можно также использовать start и stop, которые помогут в случае, если одна из этих служб начнет подглючивать. Вот полный список параметров Likewise Service Manager:
list List all known services and their status autostart Start all services configured for autostart start-only <service> Start a service start <service> Start a service and all dependencies stop-only <service> Stop a service stop <service> Stop a service and all running dependents restart <service> Restart a service and all running dependents refresh <service> Refresh service's configuration proxy <service> Act as a proxy process for a service info <service> Get information about a service status <service> Get the status of a service gdb <service> Attach gdb to the specified running service
А вот таким образом можно узнать детальную информацию об одном из сервисов:
Помните также, что Likewise Service Manager отслеживает связи служб и гасит/поднимает связанные службы в случае необходимости.
API Watchdog
Этот сервис следит через vSphere API за доступностью самого важного сервиса vCenter - VPXD. В случае сбоя, этот сервис постарается 2 раза перезапустить VPXD, и если это не получится - он вызовет процедуру перезапуска виртуальной машины механизмом VMware HA.
Эти службы инициализируются только после первой загрузки после развертывания или обновления сервисов vCenter. Затем каждые 5 минут через vSphere API происходит аутентификация и опрос свойства rootFolder для корневой папки в окружении vCenter.
Далее работает следующий алгоритм обработки отказов:
Первый отказ = Restart Service
Второй отказ = Restart Service
Третий отказ = Reboot Virtual Machine
Сброс счетчика отказов происходит через 1 час (3600 секунд)
Перед рестартом сервиса VPXD, а также перед перезагрузкой виртуальной машины, служба API Watchdog генерирует лог, который можно исследовать для решения проблем:
storage/core/*.tgz - на виртуальном модуле VCSA
C:\ProgramData\VMware\vCenterServer\data\core\*.tgz - не сервере vCenter
Конфигурация сервиса API Watchdog (который также называется IIAD - Interservice Interrogation and Activation Daemon) хранится в JSON-формате в файле "iiad.json", который можно найти по адресу /etc/vmware/ на VCSA или C:\ProgramData\VMware\vCenterServer\cfg\iiad.json на Windows-сервер vCenter:
requestTimeout – дефолтный таймаут для запросов по умолчанию.
hysteresisCount – позволяет отказам постепенно "устаревать" - каждое такое значение счетчика при отказе, число отсчитываемых отказов будет уменьшено на один.
rebootShellCmd – указанная пользователем команда, которая будет исполнена перед перезапуском ВМ.
restartShellCmd – указанная пользователем команда, которая будет исполнена перед перезапуском сервиса.
maxTotalFailures – необходимое число отказов по всем службам, которое должно случиться, чтобы произошел перезапуск виртуальной машины.
needShellOnWin – определяет, нужно ли запускать сервис с параметром shell=True на Windows.
watchdogDisabled – позволяет отключить API Watchdog.
vpxd.watchdogDisabled – позволяет отключить API Watchdog для VPXD.
createSupportBundle – нужно ли создавать support-бандл перед перезапуском сервиса или рестартом ВМ.
automaticServiceRestart – нужно ли перезапускать сервис при обнаружении сбоя или просто записать это в лог.
automaticSystemReboot – нужно ли перезапускать ВМ при обнаружении сбоя или просто записать в лог эту рекомендацию.
Многие из вас знают утилиту esxtop (о которой мы часто пишем), позволяющей осуществлять мониторинг производительности сервера VMware ESXi в различных аспектах - процессорные ресурсы, хранилища и сети. Многие администраторы пользуются ей как раз для того, чтобы решать проблемы производительности.
Но оказывается, что использование esxtop само по себе может тормозить работу сервера VMware ESXi!
Это может произойти в ситуации, если у вас к ESXi смонтировано довольно много логических томов LUN, на обнаружение которых требуется более 5 секунд. Дело в том, что esxtop каждые 5 секунд повторно инициализирует объекты, с которых собирает метрики производительности. В случае с инициализацией LUN, которая занимает длительное время, запросы на инициализацию томов будут складываться в очередь. А как следствие (при большом числе томов) это будет приводить к возрастанию нагрузки на CPU и торможению - как вывода esxtop, так и к замедлению работы сервера в целом.
Выход здесь простой - надо использовать esxtop с параметром -l:
# esxtop -l
В этом случае данная утилита ограничит сбор метрик производительности только теми объектами, которые были обнаружены при первом сканировании. Соответственно, так лучше всего ее и использовать, если у вас к серверу VMware ESXi прицеплено много хранилищ.
Как и другие документы этой серии, этот whitepaper богат различными графиками и диаграммами, касающимися производительности решения. Например, вот производительность обычного кластера VMware Virtual SAN 6.1 и растянутого с задержками (latency) в 1 мс и 5 мс:
Основные моменты, раскрываемые в документе:
Развертывание и настройка Virtual SAN Stretched Cluster
Производительность растянутого кластера в сравнении с обычным
Производительность кластера при различных отказах (хост, сайт целиком)
Лучшие практики использования растянутых кластеров
Некоторое время назад вышло обновление VMware vSphere 6.0 Update 1, после чего пользователи Onyx под Web Client заметили, что он перестал работать. Напомним, что Onyx предназначен для записи действий пользователя в клиенте vSphere, после чего они записываются в виде сценариев PowerShell.
Теперь в обновленном Onyx для VMware vSphere Web Client, который можно скачать с сайта VMware Labs, новая версия vSphere 6.0 U1 полностью поддерживается.
Причина плохого поведения Onyx проста - так как этот продукт теперь полностью завязан на VMware vCenter, то теперь любое значимое изменение оного требует отдельного апдейта.
Таги: VMware, Onyx, Update, Labs, vSphere, Web Client, PowerShell, PowerCLI
Продолжаем серию статей о решении vGate R2 от компании Код Безопасности, предназначенном для защиты виртуальной инфраструктуры VMware vSphere и Microsoft Hyper-V от несанкционированного доступа, а также для ее безопасной настройки средствами политик. Сегодня мы поговорим о новой возможности vGate R2 версии 2.8 - режимах работы, которые позволяют обеспечивать развертывание решения, его эксплуатацию, а также обработку исключительных ситуаций.
Продолжаем рассказывать о новостях компании Veeam Software напрямую с конференции VeeamOn 2015. Напомним, что про нулевой (пре-пати) и первый дни мы писали вот тут и тут.
Второй день конференции был также насыщен событиями, но основное - это, конечно же, анонс президентом кампании Ратмиром Тимашевым бесплатного продукта для резервного копирования данных Linux-систем - Veeam Backup for Linux. Напомним, что несколько ранее компания Veeam выпустила бесплатный Veeam Endpoint Backup Free, который бесплатно позволяет бэкапить данные физических Windows-серверов (для виртуальных есть Veeam Backup and Replication, у которого также есть бесплатное издание).
Не секрет, что администраторы физических Linux-систем бэкапят свои данные чем попало, а, зачастую, и не бэкапят вовсе. Иногда это делается с помощью разных скриптов и костылей, но что с ними происходит, если админ покидает кампанию? Правильно - все приходится начинать заново. Кроме того, есть проблема резервного копирования данных Linux-систем, которые находятся в облаках различных сервис-провайдеров, например, Amazon. Там вообще очень часто все работает без бэкапов.
Так что Veeam Backup for Linux - просто отличный подарок администраторам Linux-систем. Анонс продукта проходил в огромном зале в присутствии COO VMware (он на фото ниже) и нескольких сотен человек, встретивших заявление о бесплатности бэкапа для линукс с большим энтузиазмом.
Veeam Backup for Linux - это решение, работающее на базе агента, который устанавливается в виртуальную или физическую ОС Linux. В качестве основы резервного копирования используется разработанный Veeam драйвер для changed block tracking (CBT).
Продукт Veeam Backup for Linux поддерживает LVM (Logical Volume Manager), но не использует функциональность LVM Snapshot. Вместо этого используется собственный volume snapshot provider, который не имеет таких ограничений, которые есть у LVM. Это позволяет средству от Veeam делать резервные копии множества файловых систем, снимая снапшоты на блочном уровне, при этом данные снапшота находятся на выделенном устройстве хранения, а не на том же томе, с которого идет бэкап. И кроме того, только так получится сделать консистентные снапшоты в среде Linux с помощью Veeam Backup for Linux.
В первой версии решения точно будут поддерживаться ОС Debian и Red Hat, а полный список поддерживаемых линуксов будет опубликован несколько позже.
Основные функции Veeam Backup for Linux:
Возможность настройки бэкапа на различных уровнях - весь сервер целиком, уровень тома или отдельные папки и файлы. Это позволит восстаналивать как полностью сервер, так и отдельные файлы.
Администраторы получат возможность использовать pre-freeze и post-freeze сценарии для подготовки системы к резервному копированию и созданию консистентного бэкапа.
Управлять решением можно будет как из веб-коносли, так и через командную строку и файлы конфигурации.
Для тех, кто любит консоль, Veeam сделала минималистичный и приятный дизайн прогресса бэкапа и деталей об этой операции:
Veeam Backup for Linux будет поставляться вместе с SQLite, где будут храниться настройки, статистика и прочее. Не бойтесь: SQLite много ресурсов не будет использовать - только минимальные для решения задач РК.
Veeam Backup for Linux - это бесплатное решение, но если у вас уже есть Veeam Availability Suite или Veeam Backup & Replication, то вы сможете использовать бэкап-репозитории, которые вы добавили в их консолях, в качестве целевых. Это позволит проводить простой мониторинг процесса резервного копирования, получать нотификации по почте об отработавших задачах РК, шифровать файлы в бэкапах и записывать их на ленту, либо в географически удаленную локацию. В общем, все по аналогии с Veeam Endpoint Backup FREE.
Veeam Backup for Linux будет доступен в начале 2016 года. Сейчас вы можете зарегистрироваться на открытую бету - Veeam Backup for Linux beta (кто первый зарегистрируется, тому первому выдадут).
Мы уже не раз писали про VMware ESXi Embedded Host Client, который возвращает полноценный веб-клиент для сервера VMware ESXi с возможностями управления хостом и виртуальными машинами, а также средствами мониторинга производительности.
Теперь для этого продукте есть offline bundle, который можно накатывать с помощью VMware Update Manager, как на VMware vSphere 5.x, так и на VMware vSphere 6.x.
Одна из долгожданных фичей этого релиза - возможность просматривать и редактировать разделы дисков ESXi:
Если у вас есть это средство второй версии, то обновиться на третью можно с помощью следующей команды:
За прошедшие недели мы достаточно многописали о новостях с VMware VMworld 2015 (как в Америке, так и в Европе). Не так давно компания ИТ-ГРАД, ведущий хостинг-провайдер VMware IaaS в России, опубликовала свою версию основных новостей с VMworld.
Давайте посмотрим, какие анонсы показались коллегам наиболее важными:
15 самых горячих технологических новинок с VMworld 2015
Многие годы VMware формирует будущее корпоративных ИТ-технологий, продвигая идею программно-определяемого ЦОД. Несмотря на растущую конкуренцию, компания до сих пор занимает лидирующие позиции на рынке виртуализации. Столь продвинутую и технически совершенную виртуальную инфраструктуру помогают формировать и многочисленные стратегические партнеры VMware, представившие свои новинки на недавно отгремевшей конференции VMworld 2015. Мы не могли пройти мимо любопытного списка технических новшеств конференции, который опубликовали коллеги из cio.com, и отобрали 15 самых интересных новинок. Спешим поделиться.
1. Unity EdgeConnect
Если попытаться одной фразой объяснить, что делает это устройство, то получится как-то так: Unity EdgeConnect позволяет компаниям упростить и удешевить построение WAN с помощью использования технологий SD-WAN для существующего широкополосного подключения. Фактически требуется подключить такие устройства с обеих сторон (в головном офисе и филиале) и через Unity Orchestrator выполнить связь устройств буквально в пару кликов. Впрочем, лучше посмотреть своими глазами — вот коротенькое видео.
Unity EdgeConnect уже доступен для заказа и обойдется примерно в $199/мес. для каждого сайта.
2. Soha Cloud
Облако Soha Cloud позволяет добавить безопасности вашим облачным приложениям. Продукт выступает в качестве «прослойки» (AirGAP) между облачными приложениями и сетью Интернет, что уменьшает поверхность потенциальной атаки до нуля и прячет приложения от публики. Подробности о технологии можно почерпнуть на сайте SOHA.
Стоимость сервиса стартует с отметки $5/мес. на пользователя, а опробовать его можно уже сейчас.
3. PRTG Network Monitor
PRTG Network Monitor — это система мониторинга для стартапов и небольших компаний. Продукт позволяет выполнять мониторинг состояния и производительности всей инфраструктуры, включая облако и виртуальную среду (например, есть «сенсоры» для серверов VMware и виртуальных машин). Стоимость лицензии зависит от приобретаемого числа сенсоров, причем до 100 штук можно мониторить совершенно бесплатно.
Интересная возможность есть в VMware vSphere 6, которая может оказаться полезной для администраторов датацентров, которые имеют подчиненность главному ЦОД, который задает стандарты администрирования виртуальной инфраструктуры. Возьмем, например, РЖД - у них есть главный вычислительный центр (ГВЦ) и сеть информационно-вычислительных центров (ИВЦ) по всей стране, в которых, как и в ГВЦ, есть свои виртуальные инфраструктуры на платформе VMware vSphere.
Так вот, функция VMware vSphere Content Library позволяет подписать ИВЦ на обновления ГВЦ (который будет издатель/publisher), где можно создать шаблон виртуальной машины, а на уровне ИВЦ (подписчик/subscriber) администраторы этот шаблон ВМ увидят и установят. Очень удобно.
Для этого в центральном датацентре нужно перейти в раздел Content Libraries в vSphere Web Client:
Там нажимаем иконку создания нового объекта и добавляем новую библиотеку (Library):
Далее возьмем виртуальную машину, которую мы хотим превратить в шаблон (VM Template) и выберем из ее контекстного меню пункт Clone -> Clone to Template in Library:
Переходим на вкладку Related Objects и убеждаемся, что шаблон виртуальной машины добавлен в библиотеку:
Теперь, чтобы опубликовать библиотеку (Publish), нужно пойти на вкладку Manage, нажать Edit и поставить галку Publish this library externally (можно задать параметры доступа в разделе Authentication):
Уже в региональном датацентре нужно создать новую библиотеку:
И выбрать пункт Subscribed content library, указав URL центральной библиотеки паблишера:
После этого мы увидим в ней шаблон виртуальной машины, который мы создали в центральном датацентре:
Ну и из этого шаблона мы можем развернуть новую виртуальную машину в нашем региональном ЦОД на базе стандартов центра:
Как вы наверное заметили, помимо вкладки Templates, есть еще и вкладка Other Types, то есть можно публиковать не только шаблоны, но и другие объекты. Наиболее полезно будет распространять таким способом ISO-образы для гостевых ОС, а также скрипты для автоматизации различного рода операций. Удобная штука, но мало кто об этом знает.
Больше 5 лет назад мы писали о технологии VMware Storage I/O Control (SIOC), которая позволяет приоритизировать ввод-вывод для виртуальных машин в рамках хоста, а также обмен данными хостов ESXi с хранилищами, к которым они подключены. С тех пор многие администраторы применяют SIOC в производственной среде, но не все из них понимают, как именно это работает.
На эту тему компания VMware написала два интересных поста (1 и 2), которые на практических примерах объясняют, как работает SIOC. Итак, например, у нас есть вот такая картинка:
В данном случае мы имеем хранилище, отдающее 8000 операций ввода-вывода в секунду (IOPS), к которому подключены 2 сервера ESXi, на каждом из которых размещено 2 виртуальных машины. Для каждой машины заданы параметры L,S и R, обозначающие Limit, Share и Reservation, соответственно.
Напомним, что:
Reservation - это минимально гарантированная производительность канала в операциях ввода-вывода (IOPS). Она выделяется машине безусловно (резервируется для данной машины).
Shares - доля машины в общей полосе всех хостов ESXi.
Limit - верхний предел в IOPS, которые машина может потреблять.
А теперь давайте посмотрим, как будет распределяться пропускная способность канала к хранилищу. Во-первых, посчитаем, как распределены Shares между машинами:
Общий пул Shares = 1000+2500+500+1000 = 5000
Значит каждая машина может рассчитывать на такой процент канала:
Если смотреть с точки зрения хостов, то между ними канал будет поделен следующим образом:
ESX1 = 3500/5000 = 70%
ESX2 = 1500/5000 = 30%
А теперь обратимся к картинке. Допустим у нас машина VM1 простаивает и потребляет только 10 IOPS. В отличие от планировщика, который управляет памятью и ее Shares, планировщик хранилищ (он называется mClock) работает по другому - неиспользуемые иопсы он пускает в дело, несмотря на Reservation у это виртуальной машины. Ведь он в любой момент может выправить ситуацию.
Поэтому у первой машины остаются 1590 IOPS, которые можно отдать другим машинам. В первую очередь, конечно же, они будут распределены на этом хосте ESXi. Смотрим на машину VM2, но у нее есть LIMIT в 5000 IOPS, а она уже получает 4000 IOPS, поэтому ей можно отдать только 1000 IOPS из 1590.
Следовательно, 590 IOPS уйдет на другой хост ESXi, которые там будут поделены в соответствии с Shares виртуальных машин на нем. Таким образом, распределение IOPS по машинам будет таким:
Все просто и прозрачно. Если машина VM1 начнет запрашивать больше канала, планировщик mClock начнет изменять ситуацию и приведет ее к значениям, описанным выше.
Тема вебинара - "Защита виртуальных инфраструктур: комбинация встроенных механизмов платформы виртуализации и сторонних средств". Мероприятие проведет Иван Колегов, системный аналитик компании «Код Безопасности». На вебинаре будет рассказано о защите виртуальных инфраструктур с помощью встроенных механизмов платформы виртуализации и сторонних средств. Таги:
Мы часто пишем о проблемах вложенной виртуализации (nested virtualization), которая представляет собой способ запустить виртуальные машины на гипервизоре, который сам установлен в виртуальной машине. На платформе VMware ESXi эта проблема давно решена, и там nested virtualization работает уже давно, мало того - для виртуального ESXi есть даже свои VMware Tools.
Как мы недавно писали, решения для вложенной виртуализации на платформе Microsoft Hyper-V не было. При попытке запустить виртуальную машину на виртуальном хосте Hyper-V администраторы получали вот такую ошибку:
VM failed to start. Failed to start the virtual machine because one of the Hyper-V components is not running.
Все это происходило из-за того, что Microsoft не хотела предоставлять виртуальным машинам средства эмуляции техник аппаратной виртуализации Intel VT и AMD-V. Стандартная схема виртуализации Hyper-V выглядела так:
Virtualization Extensions передавались только гипервизору хостовой ОС, но не гостевой ОС виртуальной машины. А без этих расширений виртуальные машины в гостевой ОС запущены быть не могли.
Соответственно, это позволит запустить вложенные виртуальные машины на хосте, который сам является виртуальной машиной с гостевой ОС Windows и включенной ролью Hyper-V.
На данный момент работает это только с Intel VT, но по идее к релизу Windows Server 2016 должно заработать и для AMD-V.
Сфера применения вложенных виртуальных машин не такая уж и узкая. Сейчас видится 2 основных направления:
Виртуальные тестовые лаборатории, где развертываются виртуальные серверы Hyper-V и строятся модели работающих виртуальных инфраструктур в рамках одного физического компьютера.
Использование контейнеризованных приложений (например, на движке Docker) в виртуальных машинах на виртуальных хостах Hyper-V. Более подробно о Windows Server Containers можно почитать вот тут. Немногим ранее мы писали об аналогичной архитектуре на базе VMware vSphere, анонсированной на VMware VMworld 2015.
Надо отметить, что для вложенных виртуальных машин не поддерживаются следующие операции (как минимум):
Dynamic Memory
Горячее изменение памяти работающей ВМ
Снапшоты
Live Migration
Операции save/restore
Ну и вообще, вряд ли вложенная виртуализация вообще когда-нибудь будет полностью поддерживаться в производственной среде. Кстати, вложенная виртуализация на сторонних гипервизорах (например, VMware vSphere) также не поддерживается.
Для того, чтобы вложенная виртуализация заработала, нужно:
1. Использовать Windows 10 Build 10565. Windows Server 2016 Technical Preview 3 (TPv3) и Windows 10 GA - не подойдут, так как в них возможности Nested Virtualization нет.
2. Включить Mac Spoofing на сетевом адаптере виртуального хоста Hyper-V, так как виртуальный коммутатор хостового Hyper-V будет видеть несколько MAC-адресов с этого виртуального адаптера.
3. В Windows 10 нужно отключить фичу Virtualization Based Security (VBS), которая предотвращает трансляцию Virtualization Extensions в виртуальные машины.
4. Предусмотреть память под сам гостевой гипервизор и под все запущенные виртуальные машины. Память для гипервизора можно рассчитать так:
Теперь для того чтобы включить Nested Virtualization, выполните следующий сценарий PowerShell (в нем и VBS отключается, и Mac Spoofing включается):
Далее создайте виртуальную машину на базе Windows 10 Build 10565, и включите в ней Mac Spoofing (если вы не сделали это в скрипте). Сделать это можно через настройки ВМ или следующей командой PowerShell:
Set-VMNetworkAdapter -VMName <VMName> -MacAddressSpoofing on
Ну а дальше просто запускайте виртуальную машину на виртуальном хосте Hyper-V:
Таги: Microsoft, Hyper-V, Nested, Virtualization, VMachines, Windows, Server
Мероприятие пройдет 20 октября в 22-00 по московскому времени.
На вебинаре будет рассказано, почему в гиперконвергентной инфраструктуре лучше иметь 3 узла для организации отказоустойчивых хранилищ. Напомним, что мы уже писали об этой архитектуре вот тут.
После выхода новой версии платформы VMware vSphere 6 перед многими администраторами встал вопрос об обновлении различных компонентов виртуальной инфраструктуры. На крупных предприятиях, как правило, используется не только платформа VMware ESXi и сервисы управления vCenter, но и различные корпоративные продукты, такие как VMware Horizon View для инфраструктуры виртуальных ПК или VMware vRealize Operations (vROPs) для мониторинга и решения проблем.
Вот в какой правильной последовательности нужно обновлять решения VMware (если у нескольких продуктов очередь одна - их можно обновлять в любой последовательности):
Продукт
VMware
Последовательность обновления (очередность)
vCenter
Single Sign-On (SSO)
1
vRealize Automation (vRA), бывший vCloud Automation Center
2
vRealize Configuration Manager (VCM), бывший vCenter Configuration Manager
2
vRealize Business (он же ITBM - VMware IT Business Management)
2
vRealize Automation Application Services (vRAS), бывший vSphere AppDirector
3
vCloud Director (vCD)
3
vCloud Networking and Security (vCNS)
4
NSX Manager
4
NSX Controllers
5
View Composer
5
View Connection Server
6
vCenter Server
7
vRealize Orchestrator (vRO), он же vCenter Orchestrator
8
vSphere Replication (VR)
8
vCenter Update Manager (VUM)
8
vRealize Operations Manager (vROPs) / он же vCenter Operations Manager (vCOPs)
8
vSphere Data Protection (VDP)
8
vCenter Hyperic
8
vCenter Infrastructure Navigator (VIN)
8
vCloud Connector (vCC)
9
vRealize Log Insight (vRLI)
9
vSphere Big Data Extension (BDE)
9
vCenter Site Recovery Manager (SRM)
9
ESXi
10
VMware Tools
11
vShield / NSX / Edge
11
vShield App/ NSX LFw
12
vShield Endpoint / NSX Guest IDS
12
View Agent / Client
12
О проведении операций по обновлению компонентов решений VMware более подробно рассказано в статье KB 2109760. Там же приведены примеры сценариев обновления, если у вас есть определенный набор продуктов.
Кстати, помните, что после обновления на VMware vSphere 6.0 вы не сможете использовать продукт VMware Storage Appliance, который больше не поддерживается.
Этой статьёй я хочу открыть серию статей, целью каждой из которых будет описание одной из написанных мной функций PowerCLI или так называемых командлетов (cmdlets), предназначенных для решения задач в виртуальных инфраструктурах, которые невозможно полноценно осуществить с помощью только лишь встроенных функций PowerCLI. Все эти функции будут объединены в один модуль - Vi-Module. Как им пользоваться, можете почитать здесь.
На проходящей сейчас в Барселоне конференции VMworld Europe 2015 компания VMware раскрыла окончательные подробности технологии vSphere Integrated Containers (VIC), которая позволяет работать с инфраструктурой виртуализованных приложений Docker на базе существующей виртуальной инфраструктуры VMware vSphere.
Начнем обзор технологии VIC вот с этого видео, в котором показано, как поднять nginx на Photon OS:
Ключевым понятием инфраструктуры контейнеров является VCH - Virtual Container Host. На самом деле это не хост, а виртуальный объект, состоящий из ресурсов ресурсного пула (Resource Pool) VMware vSphere или кластера хостов ESXi целиком. Это позволяет создавать контейнеры в нескольких доменах в рамках одного или нескольких VCH (например, Production, Staging и Test).
Каждый VCH обслуживает собственный кэш образов, которые загружаются из публичного хаба Docker или из частных репозиториев. Файловые системы ВМ в контейнерах размещаются в виртуальных дисках VMDK, которые уже лежат на обычных VMFS-хранилищах.
Само управление инфраструктурой VIC происходит через плагин к vSphere Web Client. Также есть интерфейс командной строки и PowerCLI. Вот, например, процесс создания VCH:
Напомним, что каждый контейнер Docker размещается в отдельной виртуальной машине. Сделано это с целью лучшей управляемости и надежной изоляции приложений для безопасной и стабильной их работы. Но это было бы слишком расточительно с точки зрения потребления ресурсов, поэтому VMware использует подход VMFork - создание мгновенных клонов работающей виртуальной машины. Например, вот тут мы как раз писали о VIC-подходе.
Photon Controller использует механизм VMFork (сейчас эта технология называется VMware Instant Clone и доступна в vSphere 6) для создания мгновенных экземпляров виртуальных машин на базе Photon OS (за менее, чем 1 секунду) с нужным приложением по запросу от пользователя.
То есть, на базе Photon OS развертывается новая машина через VMFork, а в ней уже тянется контейнер из нужного репозитория.
Linux-контейнеры требуют Linx Kernel и работают как приложения в виртуальных машинах, которые могут выполнять только обозначенную контейнером задачу и не имеют никаких лишних обвесов и интерфейсов.
Также для контейнеров мапятся стандартные команды, которые доступны для виртуальных машин (Power Off / Power On). Например, если мы выключим виртуальный контейнер, это будет означать, что виртуальную машину с контейнером на борту мы удалили.
vSphere Integrated Containers на данный момент находятся в статусе Technology Preview, об их доступности будет сообщено дополнительно.
Возможно не все из вас в курсе, что есть такая полезная и бесплатная утилита как vSphere Configuration Backup, которая позволяет просто и через GUI настроить резервное копирование и восстановление конфигурации серверов VMware ESXi и баз данных SQL.
Иногда администраторам хранилищ в VMware vSphere требуется передать логический том LUN или локальный диск сервера под другие цели (например, отдать не под виртуальные системы или передать в другой сегмент виртуальной инфраструктуры). В этом случае необходимо убедиться, что все данные на этом LUN удалены и не могут быть использованы во вред компании.
Раньше это приходилось выполнять путем загрузки из какого-нибудь Linux LiveCD, которому презентован данный том, и там удалять его данные и разделы. А в VMware vSphere 6 Update 1 появился более простой способ - теперь эта процедура доступна из графического интерфейса vSphere Web Client в разделе Manage->Storage Adapters:
Теперь просто выбираем нужный адаптер подсистемы хранения и нажимаем Erase для удаления логических томов устройства (будут удалены все логические тома данного устройства):
Теперь можно использовать этот локальный диск по другому назначению, например, отдать кластеру VSAN.
Ну и также отметим, что в следующей версии утилиты ESXi Embedded Host Client компания VMware сделает возможность не только удаления таблицы разделов, но и добавит средства их редактирования:
Многие из вас в курсе, что решение StarWind Virtual SAN обеспечивает лучшую в отрасли защиту виртуальных машин на платформах VMware vSphere и Microsoft Hyper-V за счет создания стабильно работающего отказоустойчивого кластера хранилищ. Напомним, что о новых возможностях последней версии продукта StarWind Virtual SAN v8 можно прочитать здесь.
Компания StarWind часто подает решение Virtual SAN на соискание различных премий, и этот год - не исключение. Совсем недавно решение Virtual SAN было выбрано финалистом премии SVC Award. Напомним, что год назад этот продукт занял второе место в рамках этой награды.
В этом году ваш голос просто обязан привести StarWind к победе! Голосуйте за StarWind Virtual SAN:
Проголосовать можно до 13 ноября. Искренне желаем нашим коллегам в этом году взять первую премию!

 RSS
RSS